The Holy Grail: Predictive Accuracy
We want to predict
- structure
- spectra
- reactivity
- …
Many-body methods (CC, CI, PT, etc.)
- systematically improvable approximations
- expensive to apply for large systems
Want predictive accuracy on large systems: proteins, complexes, etc.
| Method | Compute | Storage |
|---|---|---|
| CCSD | \(N^6\) | \(N^4\) |
| CCSD(T) | \(N^7\) | \(N^4\) |
| CCSDT | \(N^8\) | \(N^6\) |
| CCSDTQ | \(N^{10}\) | \(N^8\) |
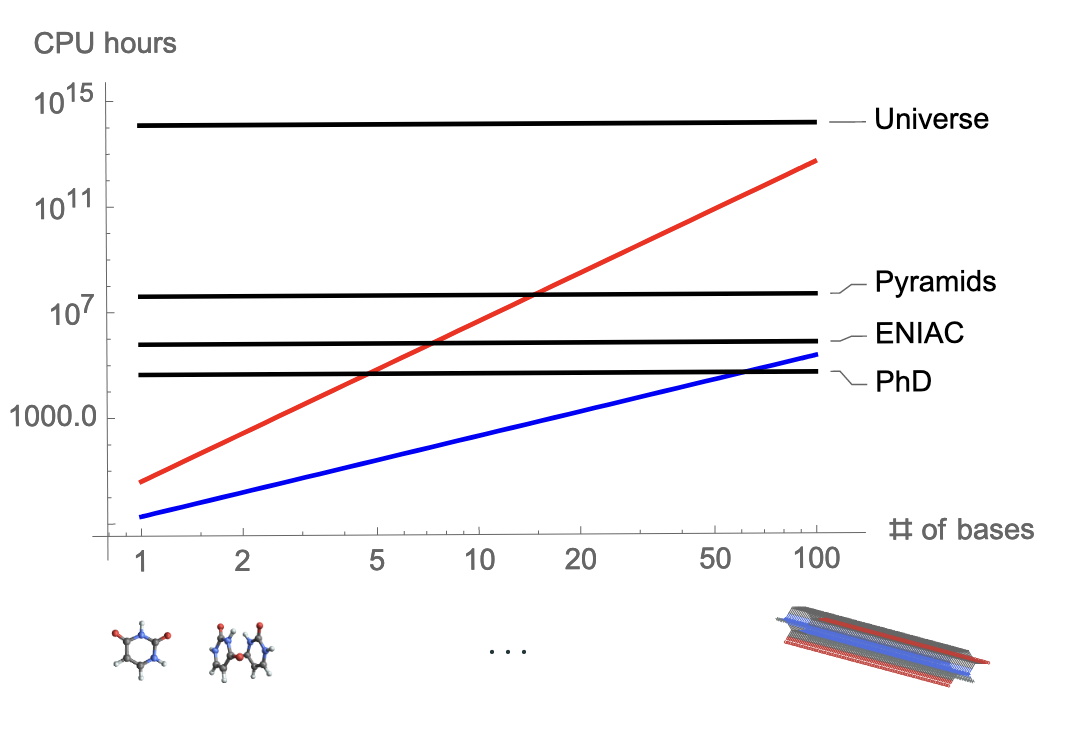
Theoretical Solutions Exist
We know how to break the scaling wall.
Fragmentation based techniques Gordon et al. (Chem. Rev., 2012)
Formalism that truncate the operator and wavefunctions directly
Use of spatially localized basis sets
- Neese et al. (J. Chem. Phys., 2009)
- Riplinger et al. (J. Chem. Phys., 2016)
- …
- Jiang et al. (J. Chem. Phys., 2025)
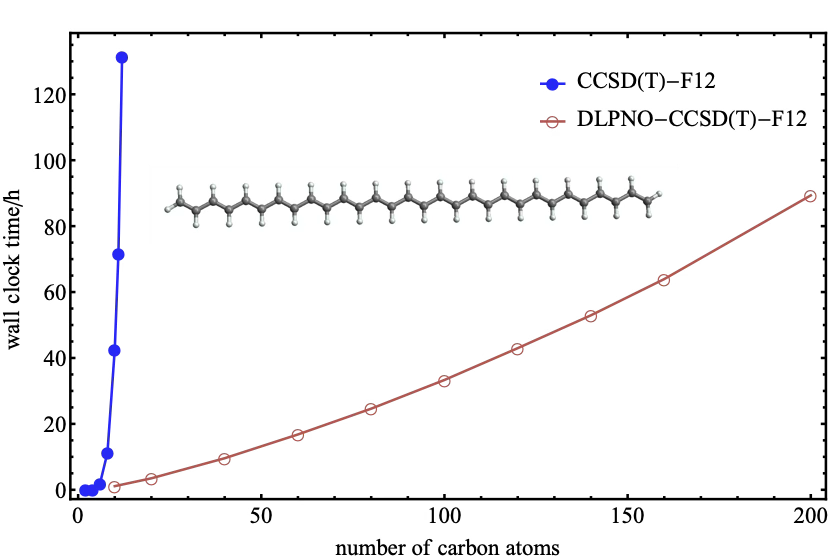
CCSD(T) \(\to\) DLPNO-CCSD(T)
\(\mathcal{O}(N^7)\) \(\to\) \(\mathcal{O}(N)\)
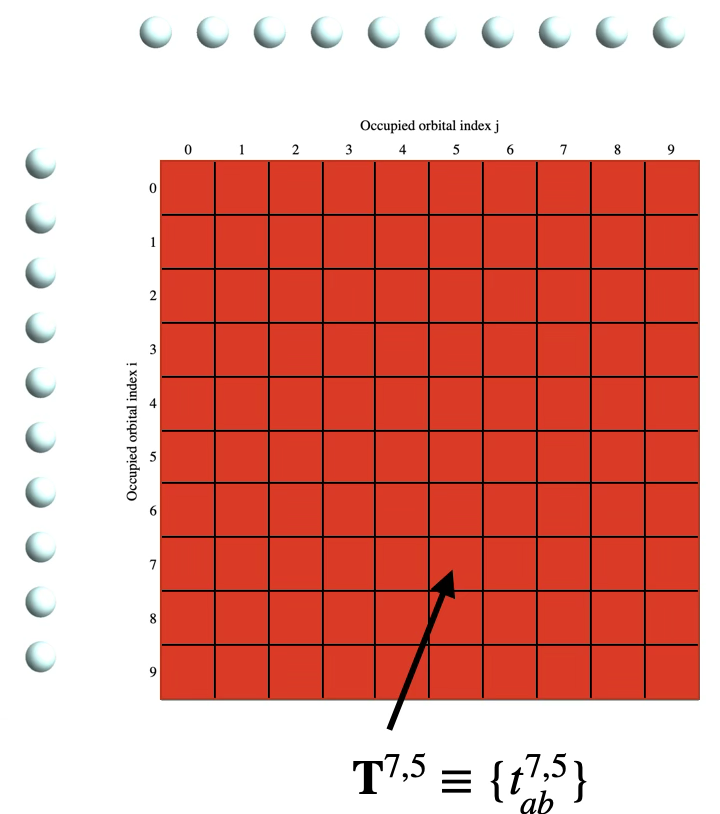
Standard Virtuals CC
\[e^\opr{T}\ket{0} =\] 
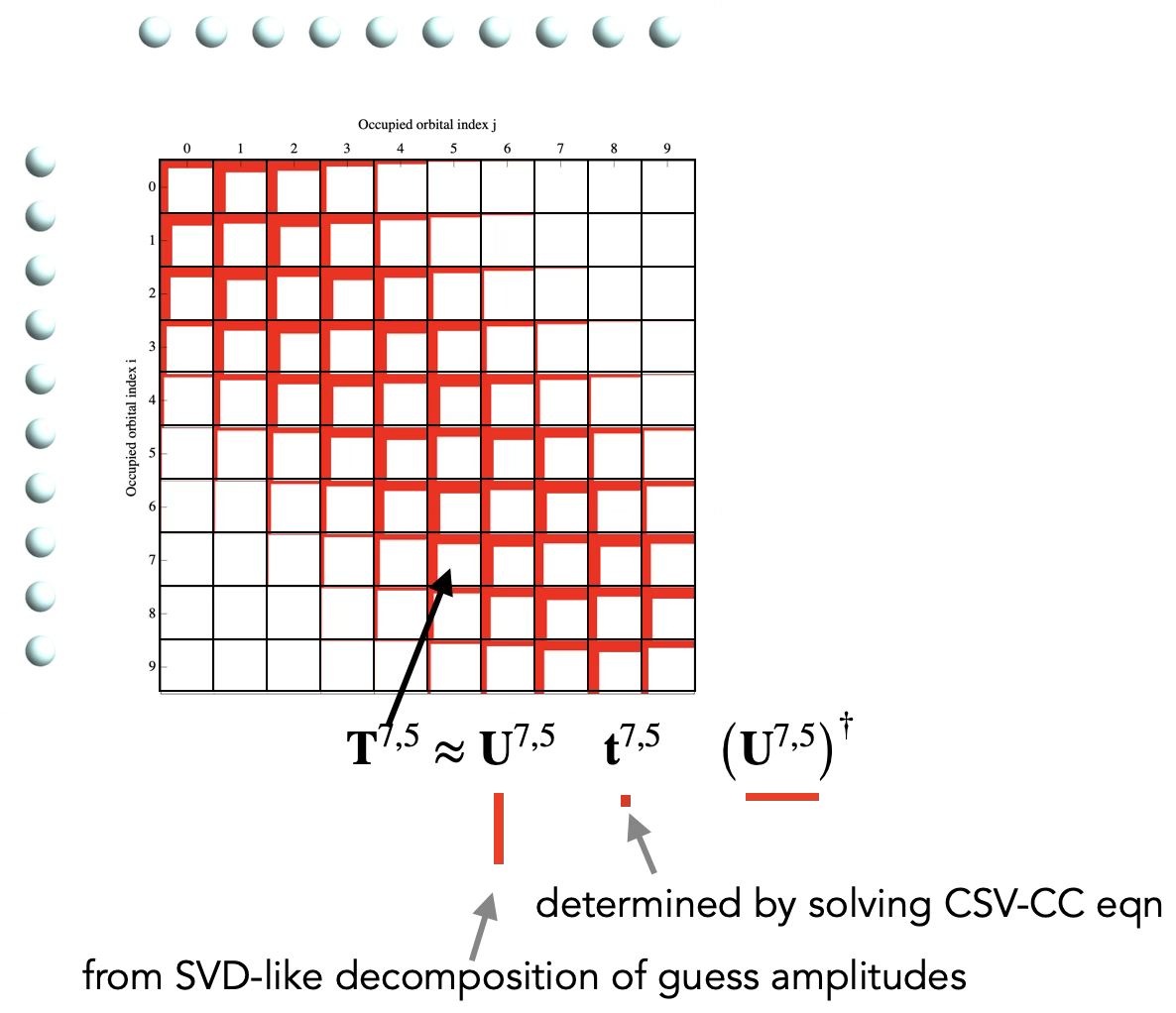
Cluster Specific Virtuals (CSV) CC
\[e^\opr{T}\ket{0} =\] 
SeQuant’s Solution: Color Graph Canonicalization
- Map the tensors networks to color graphs.
- If the graphs are isomorphic, the tensor networks are identical.
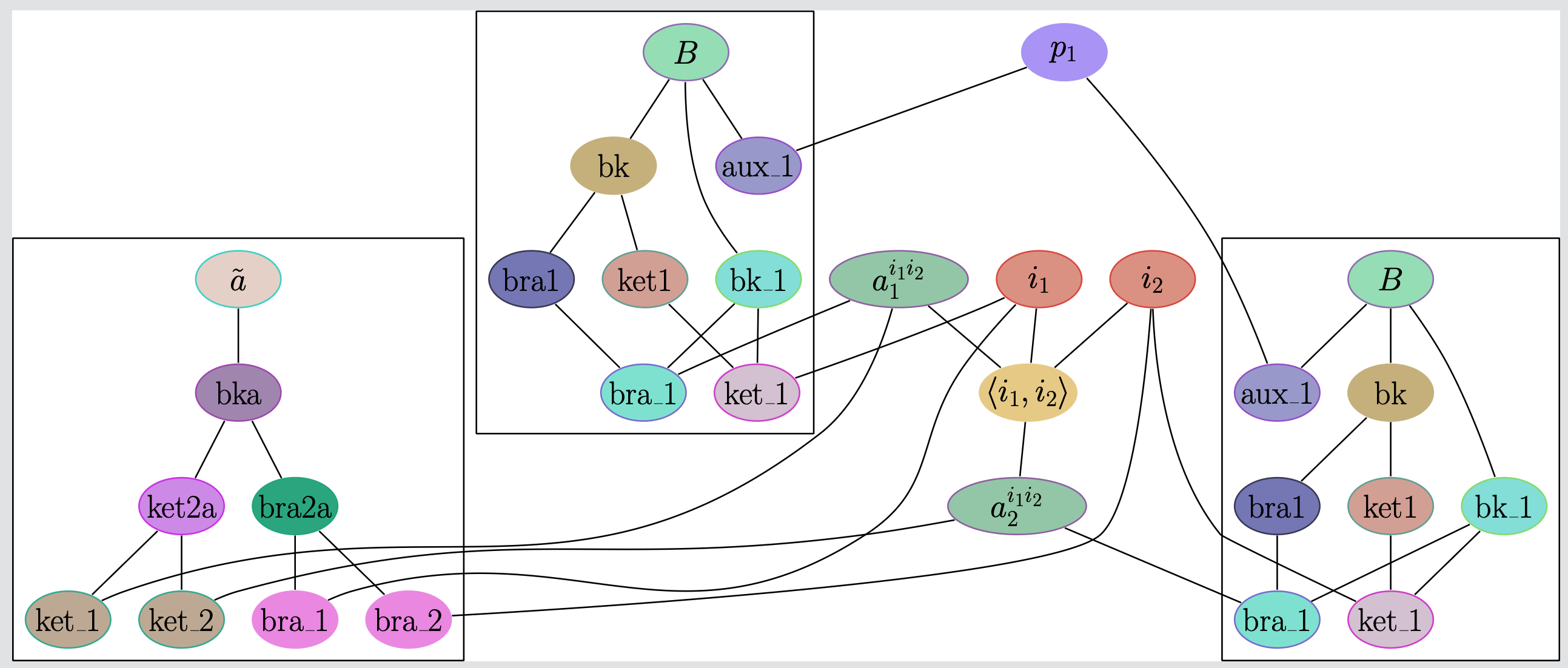
\[B_{a_1^{i_1 i_2}}^{i_1} [p_1] B_{a_2^{i_1 i_2}}^{i_2} [p_1] \tilde{a}_{i_1 i_2}^{a_1^{i_1 i_2} a_2^{i_1 i_2}}\]
Color Graph Canonicalization

- Demonstrating equivalence between \[\textbf{TN}_1 (= \tilde{a}_{i_2 i_1}^{a_2 a_1} t_{a_2}^{i_2} t_{a_1}^{i_1})\] and \[\textbf{TN}_2 (= t_{a_2}^{i_1} \tilde{a}_{i_2 i_1}^{a_2 a_1} t_{a_1}^{i_2}).\]
- Visualized vertex ordering and regrouping for corresponding tensors.
- Sign change originates from the net permutation of slots in \(\tilde{a}\) tensor (\(\textbf{TN}_2\)).
- Normalization: renamed dummy indices & lexicographically sorted the tensors
Performance of Colored Graph Canonicalizer
Canonicalizing \(D_{i_1 i_2} D_{i_3 i_4} \dots D_{i_{N-1} i_N} U^{π[i_1 \dots i_N]}\)
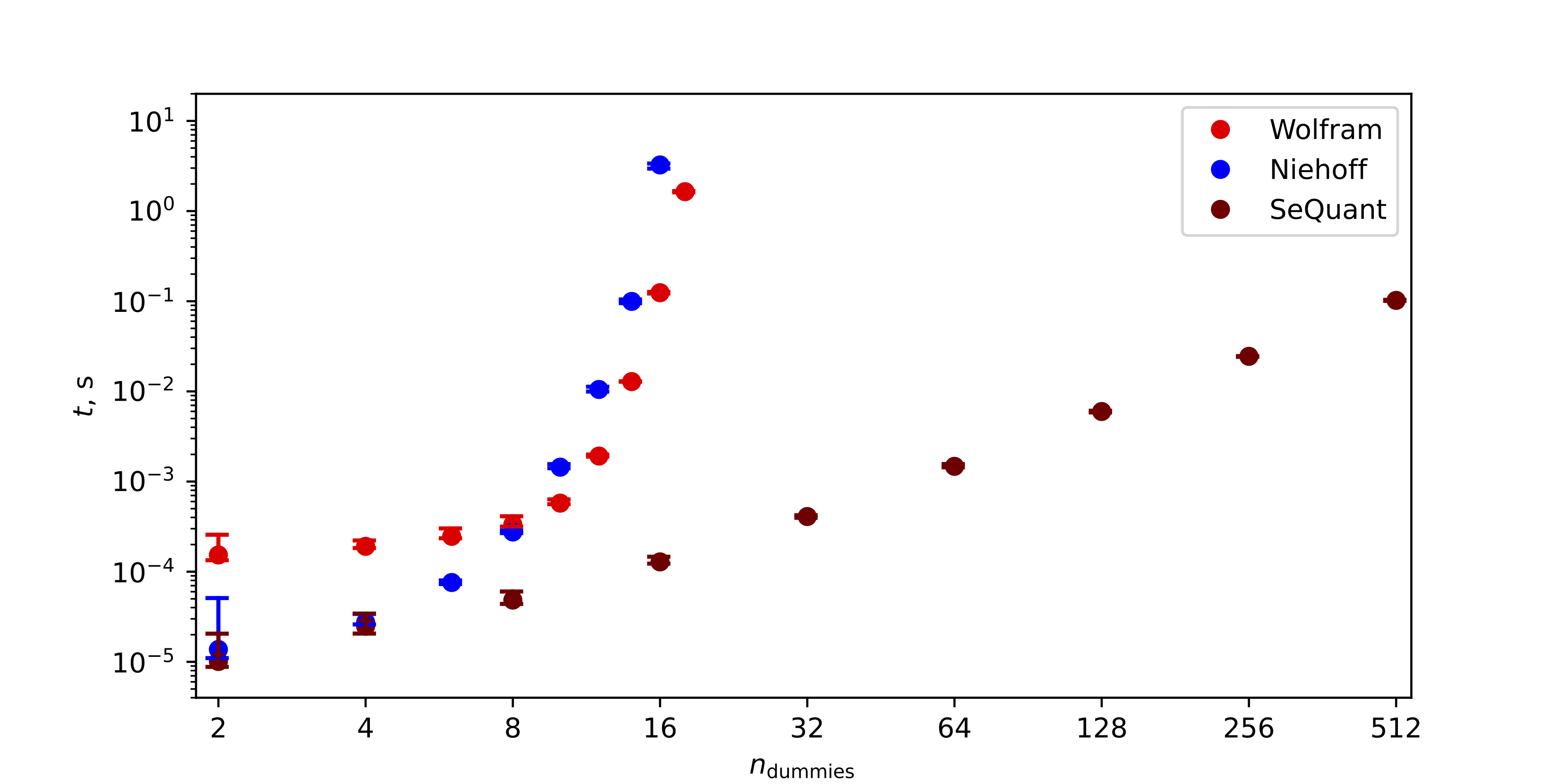
Our graph-theoretic solution surpasses Butler-Portugal-based methods in speed
Implementation
Ring-like operations support for ToT

Implemented in TiledArray.
Automated Development
We have designed SeQuant after a modern three-stage compiler.
Three stages: Front end
- general compiler fronted parses the code into an abstract syntax tree (AST)
- AST encodes different operations/symantics between nodes
- In SeQuant: the
Exprobjects from method derivation serve as the AST

\(g_{ij}^{a^{ij}b^{ij}}\left( 2t_{a^{ij}b^{ij}}^{ij} - t_{a^{ij}b^{ij}}^{ji} \right)\)
Automated Development
We have designed SeQuant after a modern three-stage compiler.
Three stages: Middle end
Intermediate Representation (IR)
- Preparatory stage for the backend/evaluation.
- Some semantics of tensor algebra might be lost as part of optimization.
- Notice the physical layout of the two \(t\) tensors.

\(g_{ij}^{a^{ij}b^{ij}}\left( 2t_{a^{ij}b^{ij}}^{ij} - t_{a^{ij}b^{ij}}^{ji} \right)\)
Automated Development
Three stages: Back end (Interpreter)
The interpreter builds on top of the IR.
Handles
- diverse data types resulting from the IR nodes
- scalars, ToS, ToT
- working with such heterogeneous result types is abstracted over a
Resultabstract class - leveraging this abstraction, the interpreter allows plug-and-play of different numerical backends
- TiledArray
- BTAS
Automated Development
Three stages: Back end (Interpreter)
The interpreter builds on top of the IR.

Results
SeQuant—a C++ library/framework for
Symbolic Derivation: wide range of theories: including PNO-CC
Automatic Evaluation: let code compilation not break our workflow
Performant and Scalable:
- implements various optimizations for improved performance
- supports auto evaluation on HPC nodes out of the box (using
TiledArraytensor framework)
Extensible Architecture: more numerical tensor frameworks and quantum chemistry packages? welcome
- e.g. Köhn group, University of Stuttgart

Results
How about CSV-CC
- We can automatically implement CSV-CC methods of arbitrary order
- We can already reproduce the results of manually implemented PNO-CC
- Clement et al. (J. Chem. Theory Comput., 2018)
However
We are facing some challenges regarding memory bottlenecks.

Acknowledgments

- Prof. Edward Valeev
- Department of Chemistry
- Joli, Esker, John
- Collaborators
- Robert, Saurabh, Saday
- My research committee
- T. Daniel Crawford
- Diego Troya
- Nicholas Mayhall
- Current and past group members
- People from all walks of my life


